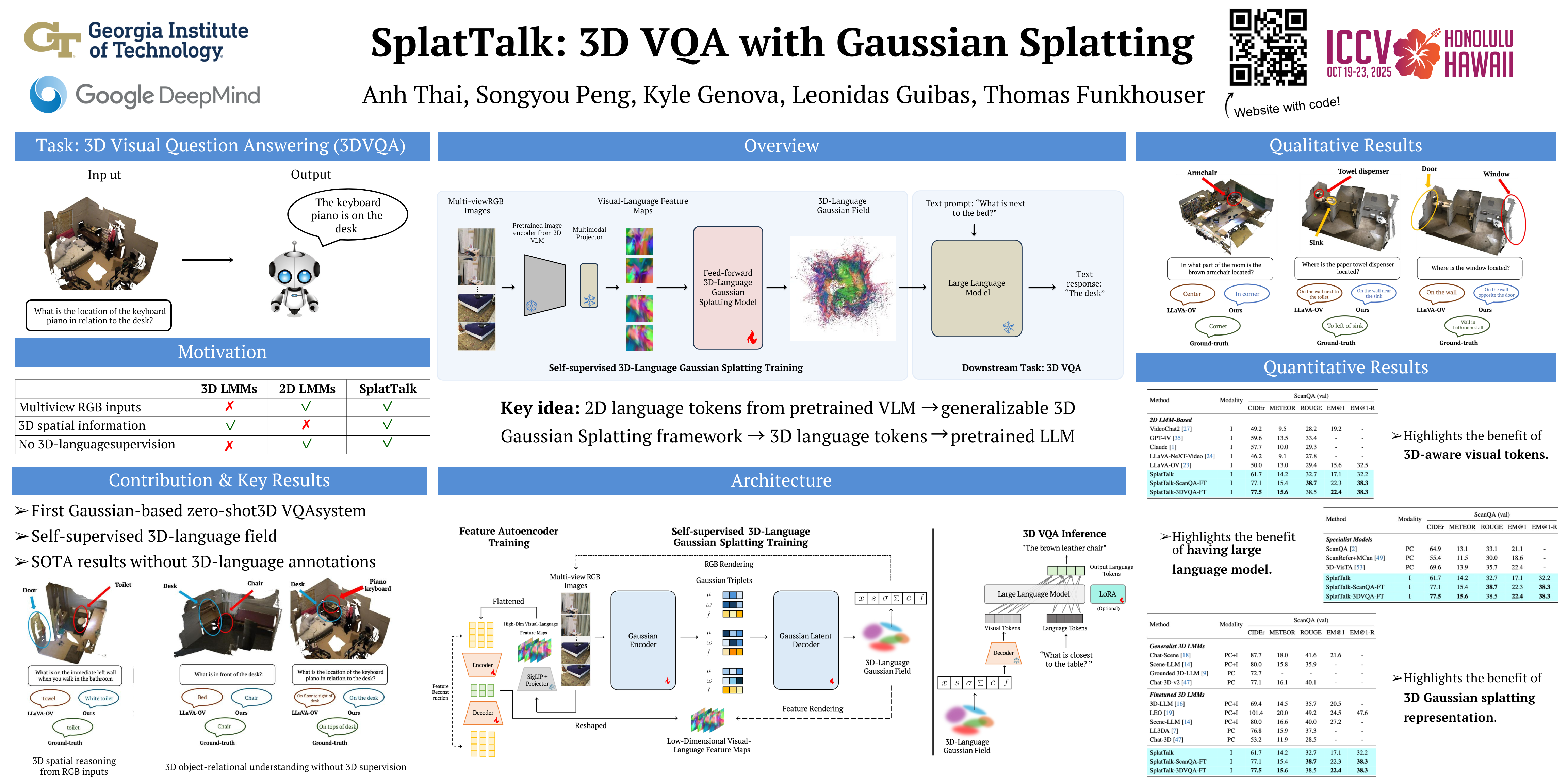
Overview of SplatTalk. We propose a self-supervised 3D-Language Gaussian Splatting model trained from multi-view RGB images. First, images are encoded using a pretrained 2D Vision-Language Model (VLM) and projected into visual-language feature maps via a multimodal projector. These feature maps are then learned within a feed-forward 3D-Language Gaussian Splatting model, producing a 3D-Language Gaussian Field that encodes spatial and semantic information in 3D space. During inference, the 3D Gaussian features are directly queried by a Large Language Model (LLM) to perform 3D question-answering (3D VQA) tasks.